Overview
This article explores the pros and cons of byte-level file replication vs block-level disk replication in a high availability cluster. We are looking at volume of replicated data, impact on application data organization, recovery time, simplicity of implementation.

The following comparative tables explain in detail the byte-level file replication implemented by SafeKit, a high availability software product.
Pros and cons of byte-level file replication vs block-level disk replication
| Cluster with byte-level file replication
|
Cluster with block-level disk replication
|
| Product | |
| SafeKit on Windows and Linux | Disks replication products as DRBD |
| Application data organization | |
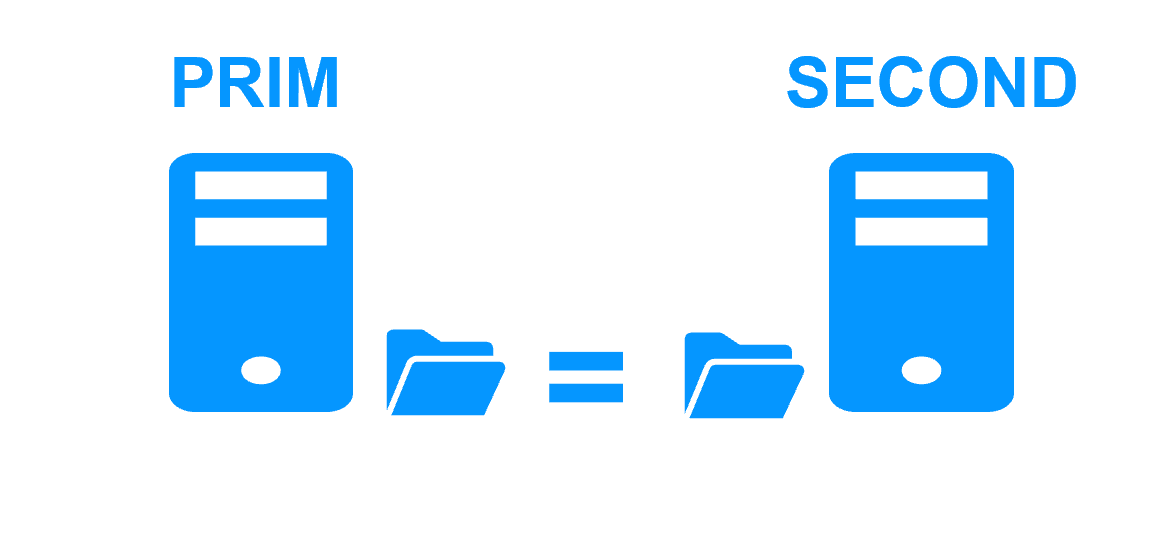
| 0 impact on application data organization with SafeKit.
Just define directories to replicate in real-time. Even directories inside the system disk can be replicated. |
Impact on application data organization.
Special configuration of the application to put its data in a replicated disk. Data in the system disk cannot be replicated. |
| Data replication | |
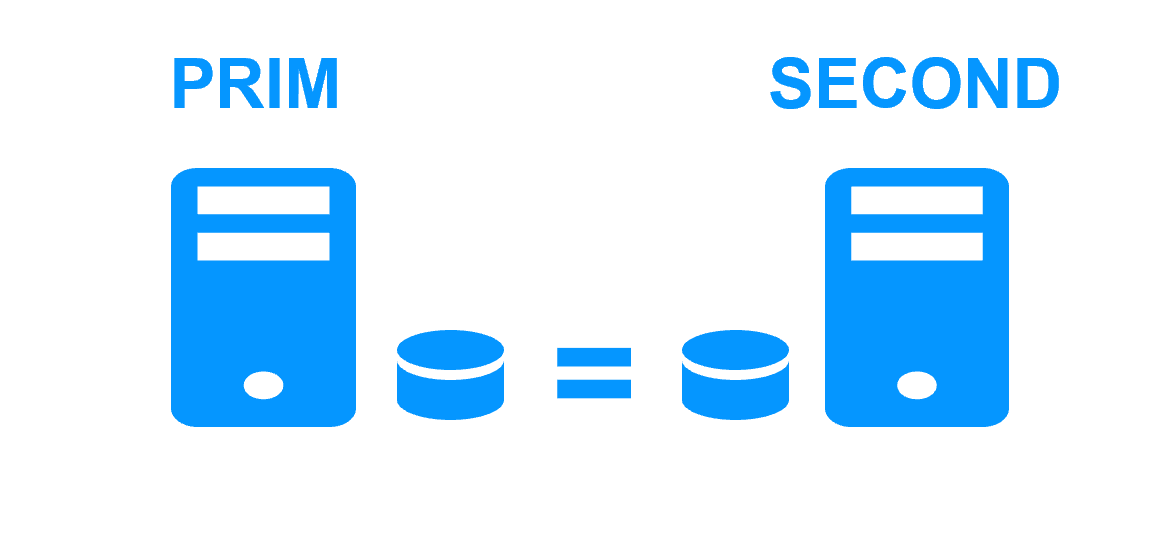
| Synchronous byte-level file replication.
Replicates file modification operations generated by application activity No meta data are replicated. |
Replicate all data modified inside a replicated disk.
Application data plus meta data are replicated. For instance, last access time on a file is replicated (last access time is modified each time the file is read). |
| Complexity of deployment | |
| No - install a software on 2 servers | Yes - require specific IT skills to configure OS and replicated disk |
| Failover | |
| Just restart the application on the second server. | Remount the file system on the replicated disk.
Pass the recovery procedure on the file system. And then restart the application. |
| Failback | |
| Automatic failback.
Resynchronization of data on the secondary server without stopping the application on the primary server. No application failover while data are not resynchronized. |
All products are not at the same level of features. |
| Quorum and split brain | |
| Application executed on a single server after a network isolation (split brain).
Coherency of data after a split brain. No need for a third machine or a quorum disk or a special heartbeat line for split brain. |
Require a special quorum disk or a third quorum server to manage split brain. |
| Suited for | |
| Software editors which want to add a simple high availability option to their application | Enterprise with IT skills in clustering. |






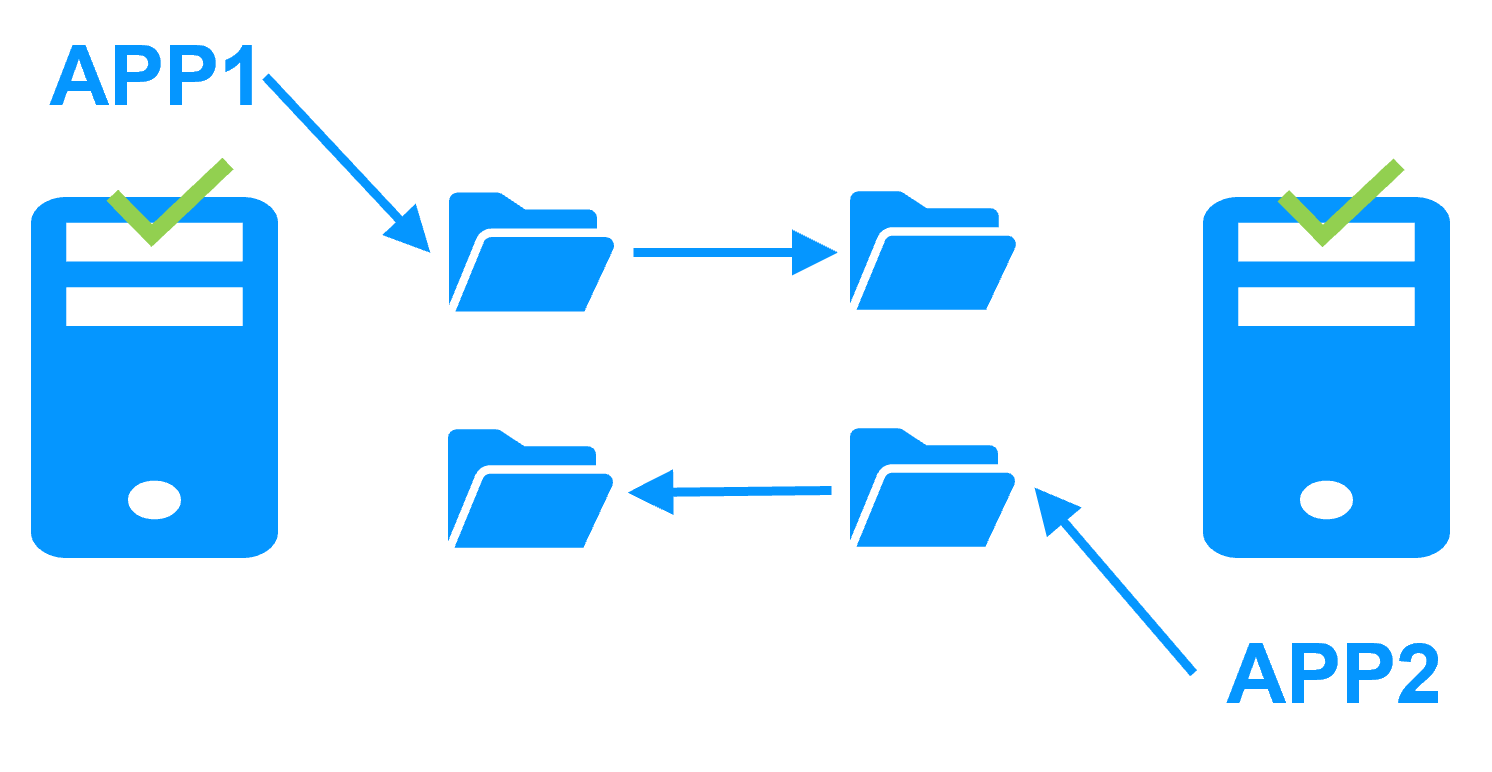
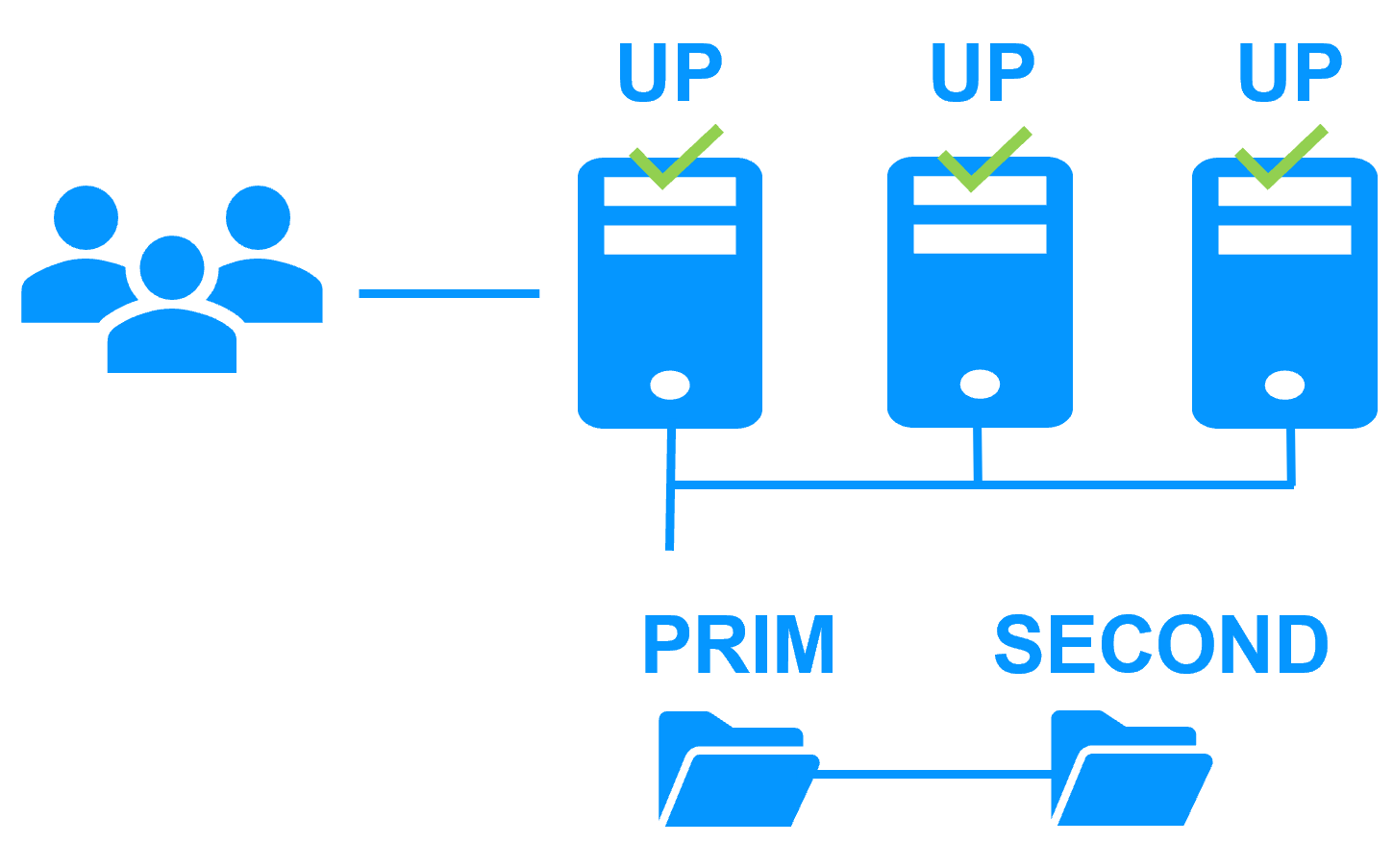
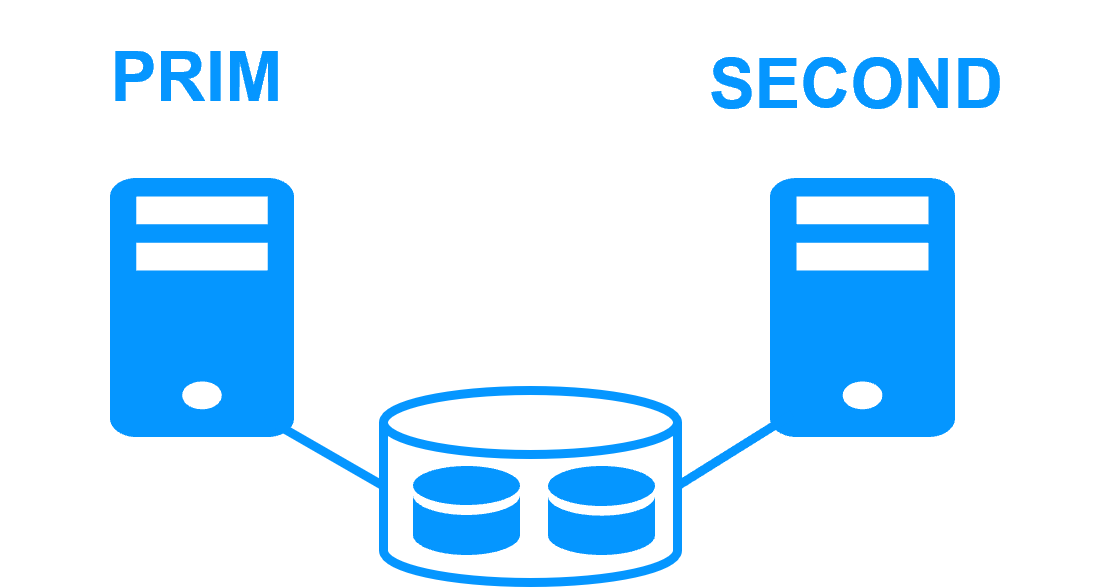
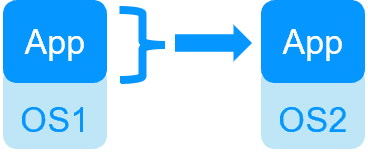
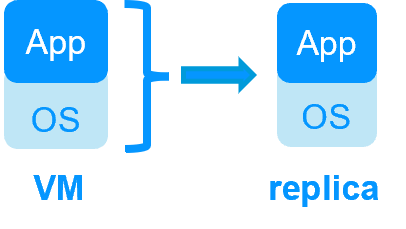









Step 1. Real-time replication
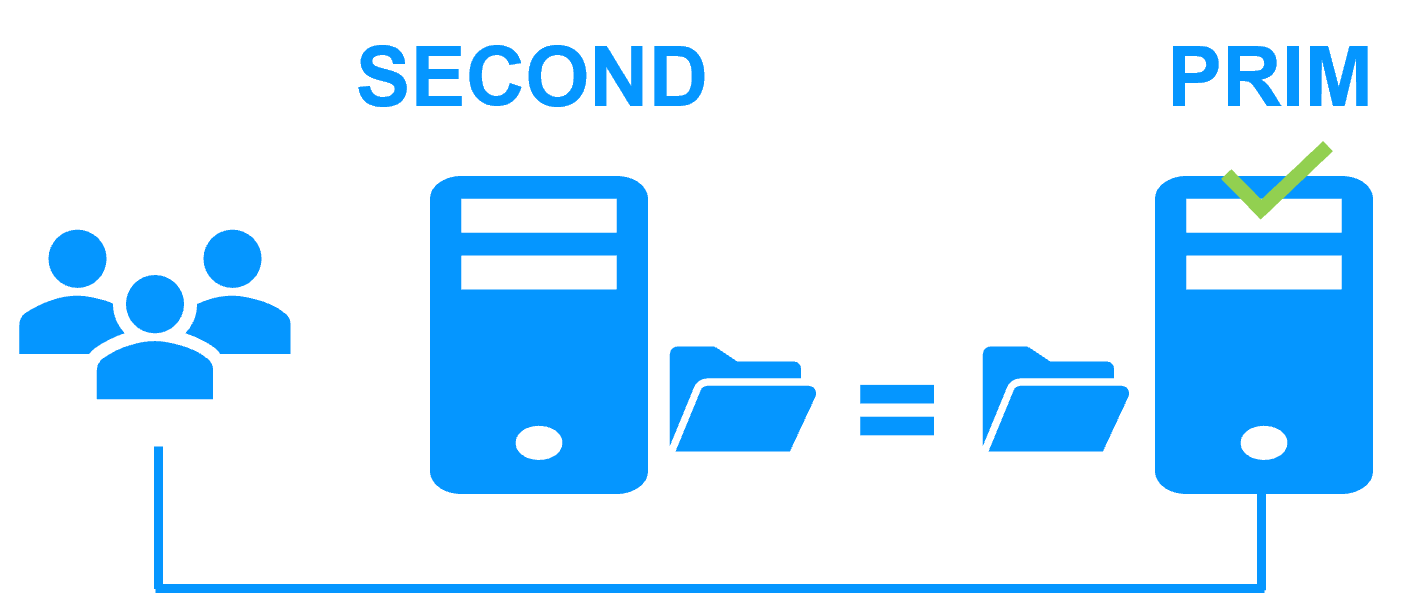
Server 1 (PRIM) runs the application. Clients are connected to a virtual IP address. SafeKit replicates in real time modifications made inside files through the network.
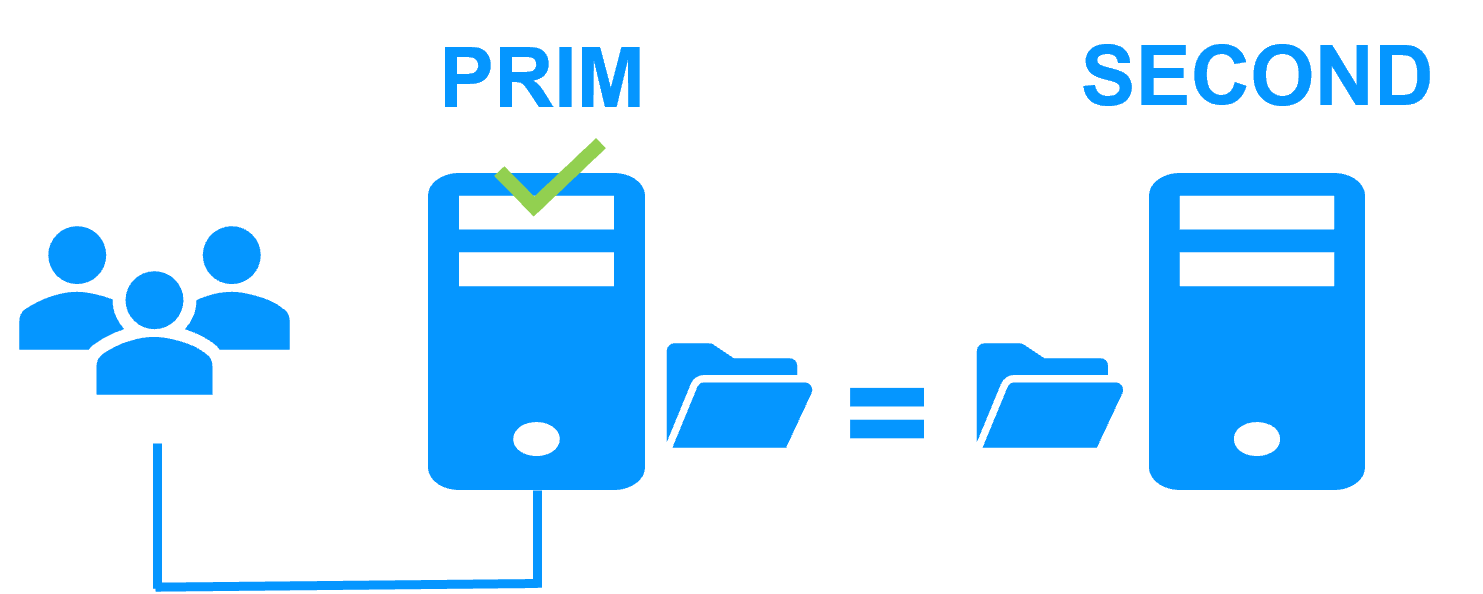
The replication is synchronous with no data loss on failure contrary to asynchronous replication.
You just have to configure the names of directories to replicate in SafeKit. There are no pre-requisites on disk organization. Directories may be located in the system disk.
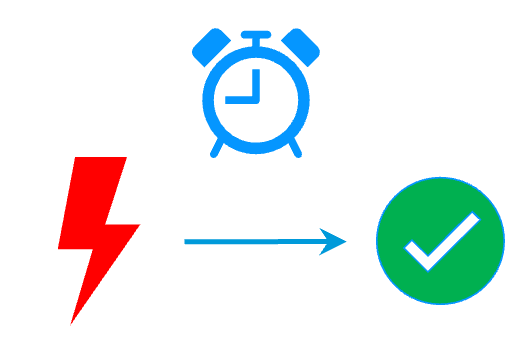
Step 2. Automatic failover
When Server 1 fails, Server 2 takes over. SafeKit switches the virtual IP address and restarts the application automatically on Server 2.
The application finds the files replicated by SafeKit uptodate on Server 2. The application continues to run on Server 2 by locally modifying its files that are no longer replicated to Server 1.
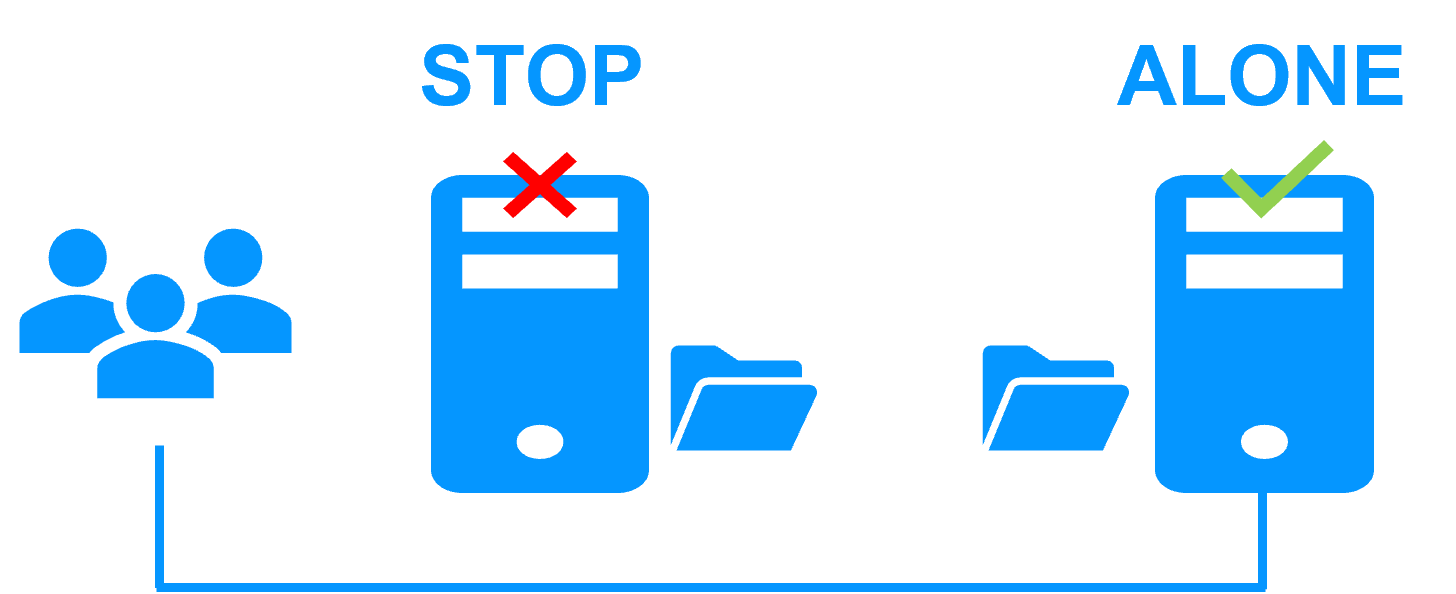
The failover time is equal to the fault-detection time (30 seconds by default) plus the application start-up time.
Step 3. Automatic failback
Failback involves restarting Server 1 after fixing the problem that caused it to fail.
SafeKit automatically resynchronizes the files, updating only the files modified on Server 2 while Server 1 was halted.
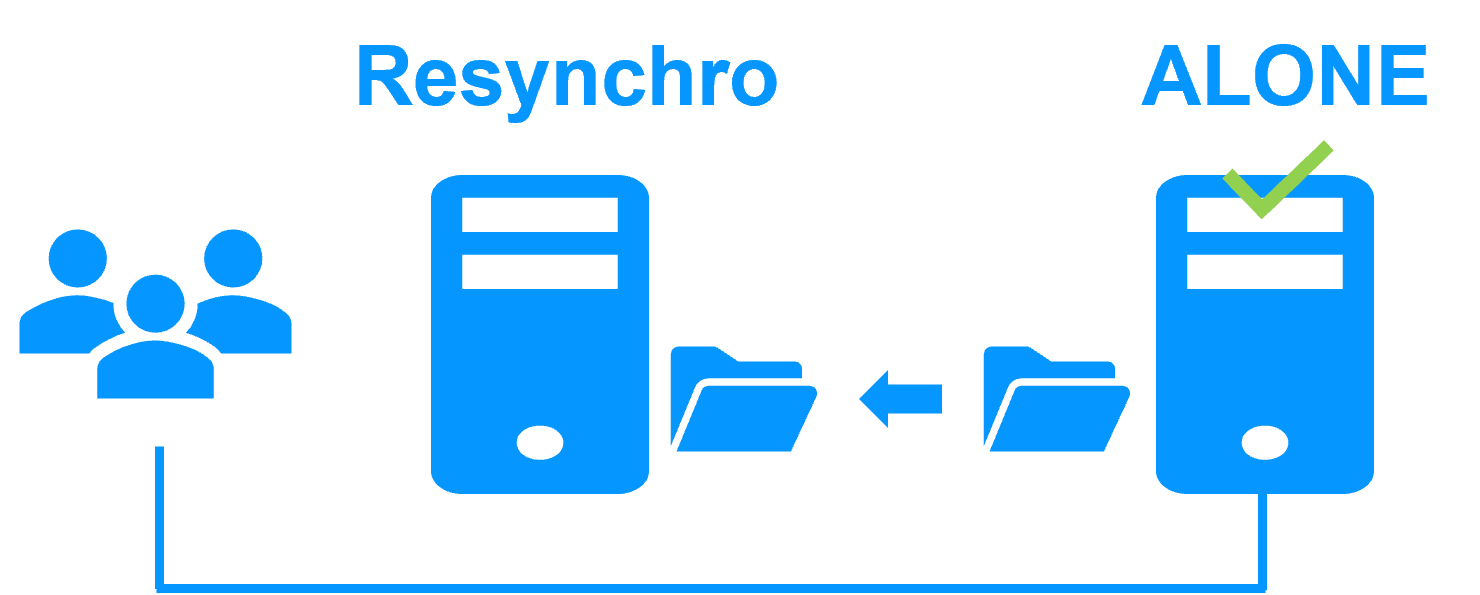
Failback takes place without disturbing the application, which can continue running on Server 2.
Step 4. Back to normal
After reintegration, the files are once again in mirror mode, as in step 1. The system is back in high-availability mode, with the application running on Server 2 and SafeKit replicating file updates to Server 1.
If the administrator wishes the application to run on Server 1, he/she can execute a "swap" command either manually at an appropriate time, or automatically through configuration.
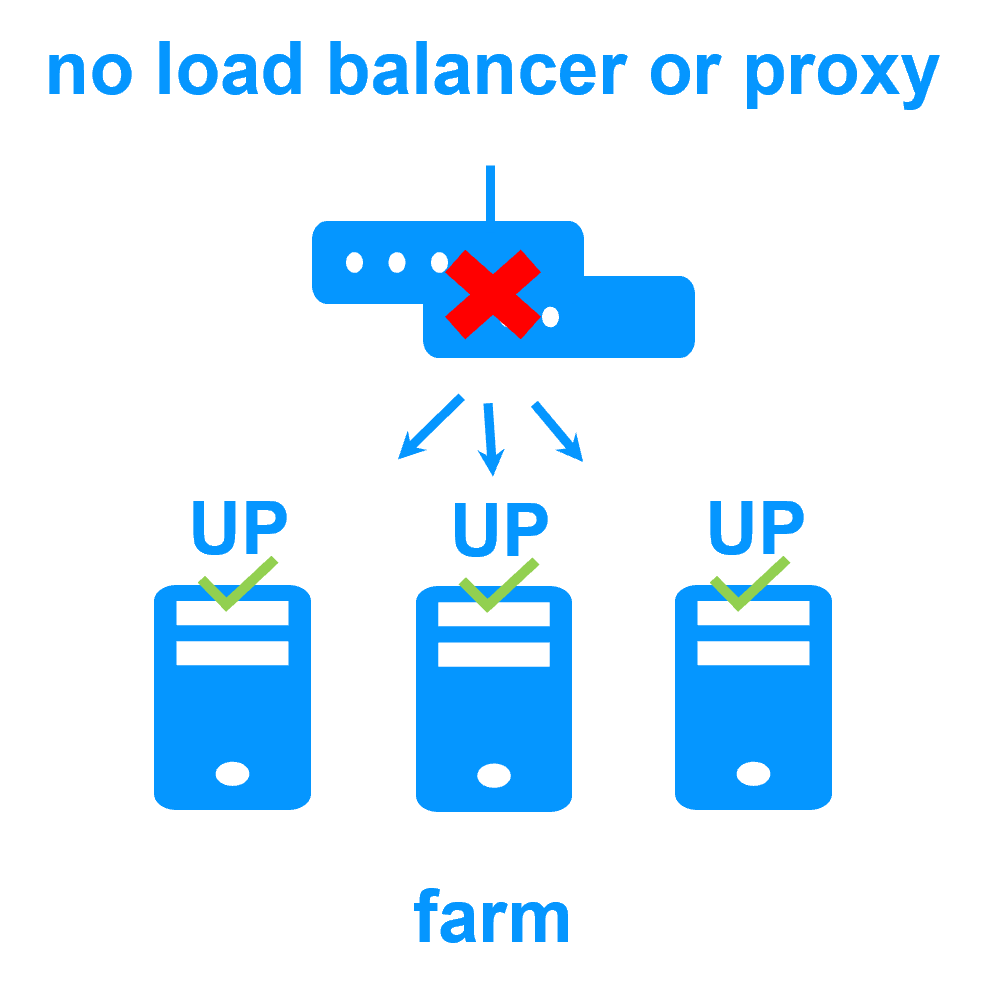
Network load balancing and failover |
|
| Windows farm | Linux farm |
| Generic Windows farm > | Generic Linux farm > |
| Microsoft IIS > | - |
| NGINX > | |
| Apache > | |
| Amazon AWS farm > | |
| Microsoft Azure farm > | |
| Google GCP farm > | |
| Other cloud > | |
